We've Been Building Pipelines Wrong. Here's How to Fix Them!
We've been building code pipelines wrong for years. Here's how to fix them...
Quick Note
When reading this post, take the terminology as generically as possible. Treat the technologies / products mentioned as exemplars only.
For example, "Artifact" in this post refers to any deployable unit. Read that as a container image, a zip file or a single JSON file if you wish.
The Problem with "with"
If someone asked you to describe your pipeline, I bet you would want to describe something like this:
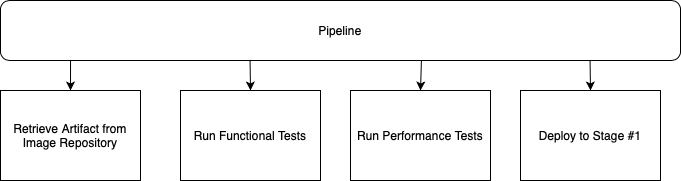
However, I bet what you'd actually describe is something like this:
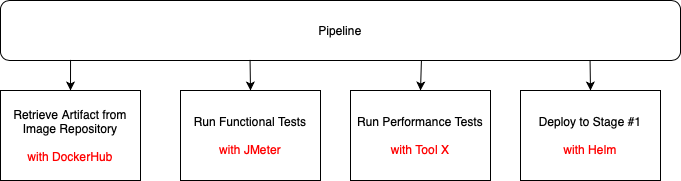
As mentioned previously, the tools above are only examples, replace with the tools you use.
As soon as you mention the tooling you use to achieve those steps, you have already introduced several problems:
- Your pipeline logic is now tightly coupled to the tooling that delivers that logic.
- Maintenance is difficult. You need to understand (and be able to code) all of those third party tool APIs. In the above example, someone in your organisation needs an in-depth knowledge of DockerHub integration strategies, JMeter APIs, whatever integration options Tool X provides and of course, Helm.
- Upgrades: Want to upgrade Tool X to the latest version? Has the API contract changed on their end? Will upgrading this tool break your pipeline?
- Copy / pasted code (and bugs): Most likely, once you've got one pipeline built, you're going to be copy and pasting that same integration code into other services, apps and teams pipelines. Every copy and paste introduces redundant code and repeated bugs across multiple teams and departments.
- Switching tools: Want to replace JMeter with NeoLoad or Gatling? Fine - first go away and understand how NeoLoad's APIs work then come back and break the pipeline while you change the tool. Then hope it works!
Consequences
The consequences of the above are stark:
- There is no separation of concern between what the pipeline does (logic) and how it implements it (tooling).
- Pipelines are copy and pasted, bugs and vulnerabilities flowing alongside.
- Pipelines are fragile: once built, everyone is very reluctant to touch them again in case everything breaks.
- They become outdated but see point above, everyone is too scared to touch them.
- DevOps engineers spend more time reacting to "Help! the pipeline is broken" than enhancing it.
The Solution?
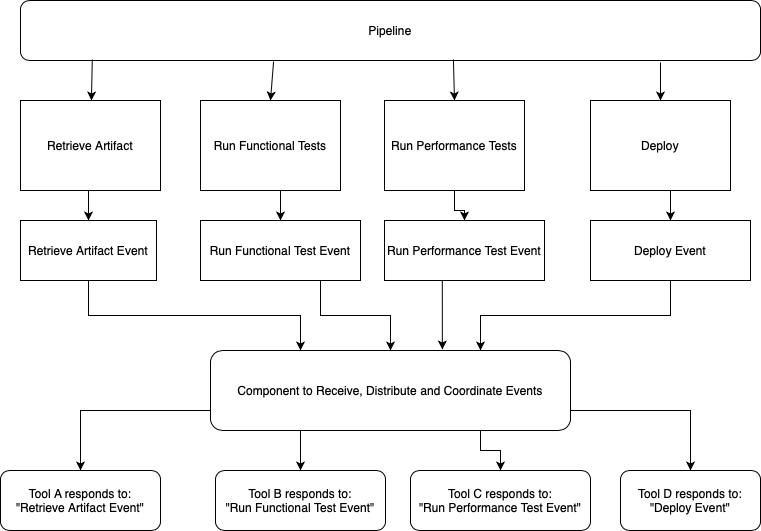
How about decoupling the pipeline logic (the what) from the tooling (the how). We could do this in the following way:
- Your pipeline uses an event based workflow which says "do the retrieval workflow"
- This event is sent to some co-ordination component
- The component distributes the event to all listening
- Someone listening says "I have the capability to respond to that event. I'll do it"
- That individual (or service) responds with: I'm starting. Then, I'm finished and here's your status.
- The middleware coordinates the status and and extra information back to the pipeline via an event.
Additional Benefits
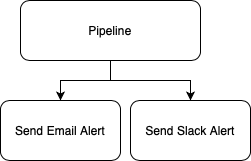
Take another common usecase of a pipeline. At some point you'll want to send an alert outbound to a third party tool to inform someone of a status. It might look like this:
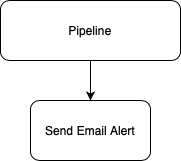
Again, you will have built specific integrations into that step to tightly couple your email servers and settings with the pipeline.
What happens if you want to replace email with a JIRA ticket or a Slack message or a problem notification into a monitoring tool? That's right - rip and replace.
What happens if you want to send alerts to two places? Two integrations, two sets of APIs with which to integrate. Two sets of potential bugs. All code managed and updated by you.
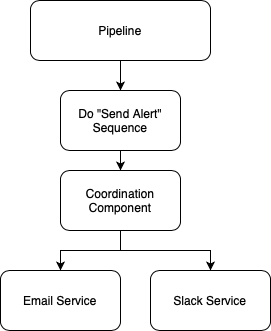
A Better Way
How about replacing this logic with a "send alert" sequence of tasks? Your pipeline sends that event and whichever tools are configured to listen for that event get to work.
No longer want email alerts? Fine. Just uninstall the email service (or tell it to stop listening for "send alert" events) from the coordination component and your emails stop.
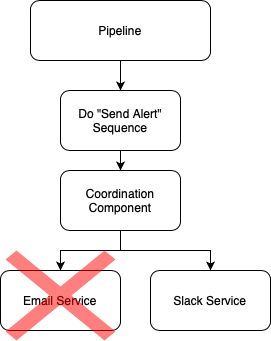
Zero changes to your pipeline and most likely, someone else has already written the "slack service" for you - so zero code upkeep or API knowledge required!
Concerns About This New Flow
At this point you probably think two things:
- "This sounds like an event bus. I'll use that." - Bear with me, I'll explain why this "coordination component" is more than an event bus later in the article.
- "What's the catch?"
My concerns here would be:
- I hope the event descriptions, payloads and schemas are not proprietary. I hope that using this workflow doesn't lock me into a particular vendor or methodology.
- Ideally I hope that there is an open source version of this "co-ordination component" available otherwise I'm again locked into a particular vendor.
Both of these concerns are valid, but both can be answered in the negative:
- The events that your pipeline send are HTTP based requests in the open source CloudEvents format. No vendor lock-in and tool interoperability guaranteed.
- The "co-ordination component" is also a CNCF Sandbox project called Keptn, so no vendor (or lock-in) there either.
One More Usecase: Evaluating an SLO
Imagine the pipeline wishes to evaluate an SLO. There is actually a "sub" workflow involved here:
- Define the SLIs
- Define a source (or sources) for the SLI data
- Retrieve the metrics from the above data source(s)
- Judge the retrieved SLIs against the SLO
- Output a result:
pass,warningorfail
It would be really nice if our tool could encapsulate and understand that sub-sequence so our pipeline only has to ask for an SLO evaluation and the tooling does the rest automatically.
Good news, it does!
Just an Event Bus?
See above - Keptn is not just an event bus. It is much more and exactly what depends on the usecase that you bring to Keptn or your role within an organisation.
This post is focused on your first steps of migrating away from an existing pipeline, piece by piece, to Keptn. However you could use Keptn to define your complete end-to-end delivery pipeline.
Here is an example of a working Keptn pipeline definition. It has 3 stages: dev, hardening and production.
The dev stage contains two tasks: deployment and release (remember that the tooling which actually does these tasks is defined elsewhere). hardening is only triggered when a the delivery finished in dev message is broadcast. Similar is true for production stage but it listens for the delivery sequence in hardening is finished message.
apiVersion: spec.keptn.sh/0.2.0
kind: "Shipyard"
metadata:
name: "shipyard-example"
spec:
stages:
- name: "dev"
sequences:
- name: "delivery"
tasks:
- name: "deployment"
- name: "release"
- name: "hardening"
sequences:
- name: "delivery"
triggeredOn:
- event: "dev.delivery.finished"
tasks:
- name: "deployment"
- name: "release"
- name: "production"
sequences:
- name: "delivery"
triggeredOn:
- event: "hardening.delivery.finished"
tasks:
- name: "deployment"
- name: "release"
In Summary
If you're struggling under the weight of multiple complex, duplicated or legacy pipelines. Give Keptn a look.
It can do a lot more and is basically a reference SRE template for continuous delivery and automated rollbacks - but more on that in future posts.
If you want to know more about Keptn, reach out to me on LinkedIn and we can chat.